- Kontakt
-
stefan.bente[at]th-koeln.de
+49 2261 8196 6367
Discord Server
Prof. Bente Personal Zoom
- Adresse
-
Steinmüllerallee 4
51643 Gummersbach
Gebäude LC4
Raum 1708 (Wegbeschreibung)
- Sprechstunde nach Vereinbarung
- Terminanfrage: calendly.com Wenn Sie dieses Tool nicht nutzen wollen, schicken Sie eine Mail und ich weise Ihnen einen Termin zu.

In Vaughn Vernon’s “Red Book,” aggregates are defined as clusters of domain objects that are treated as a single unit for data changes. They are used to enforce consistency and encapsulate the business rules within a domain model. Aggregates often consist of an aggregate root entity, which is the primary entry point for accessing and modifying the data within the aggregate, along with other related entities and value objects. Aggregates are conceptionally bound to Domain Events, which are used to communicate changes to the outside world. Together, both concepts form the core of an event-driven architecture.
The “Red Book” as a Base for Designing Event-Driven Systems
Vaugn Vernon’s “Red Book” [Vernon, 2013] is a very good source for designing event-driven systems. The main concepts to be understood from this book are Domain Events (chapter 8, p. 285 - 332) and Aggregates (chapter 10, p. 347 - 388). Both concepts are closely related, and can be seen as the conceptual base for any event-driven system.
For aggregates, Vernon defines four rules for designing aggregates, which we will briefly summarize here. I will mostly use quotes from the book, as they are very concise and to the point.
Rule 1: Model True Invariants in Consistency Boundaries
This essentially means that you should model your aggregates in a way that they are consistent at all times. This is achieved by defining invariants, which are rules that must always hold true.
There are different kinds of consistency. One is transactional consistency, which is considered immediate and atomic. There is also eventual consistency. When discussing invariants, we are referring to transactional consistency.
[Vernon, 2013, p. 353f.]
A properly designed Aggregate is one that can be modified in any way required by the business with its invariants completely consistent within a single transaction.
[Vernon, 2013, p. 354]
The consequence of this is that in one transaction, you can only modify one aggregate and never more than one aggregate. That’s why Vernon speaks of “consistency boundaries”. He also defines some possible exceptions to this rule and the other rules (p. 367ff.), but advises to handle exceptions with care.
Rule 2: Design Small Aggregates
According to Vernon, large aggregates are an anti-pattern.
[A] large-cluster Aggregate will never perform or scale well. It is more likely to become a nightmare leading only to failure. It was deficient from the start because the false invariants and a desire for compositional convenience drove the design, to the detriment of transactional success, performance, and scalability.
[Vernon, 2013, p. 356]
When looking at domain models, you should be aware that in a real-life system, you might easily run into massive scalability problems if you design too large aggregates.
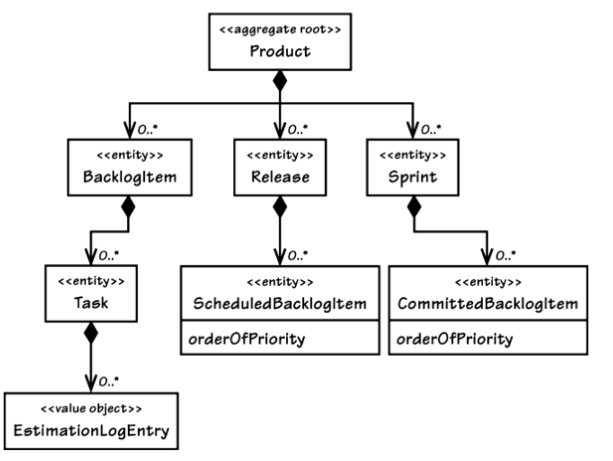
Example for an overly large aggregate [Vernon, 2013, fig. 10.3, p. 356]
Don’t let the “0..*” fool you; the number of associations will almost never be zero and will keep growing over time.
[Vernon, 2013, p. 356]
Rather, limit the Aggregate to just the Root Entity and a minimal number of attributes and/or Value-typed properties. The correct minimum is however many are necessary, and no more.
[Vernon, 2013, p. 357]
Niclas Hedhman reported that his team was able to design approximately 70 percent of all Aggregates with just a Root Entity containing some Value-typed properties. The remaining 30 percent had just two to three total Entities. This doesn’t indicate that all domain models will have a 70/30 split. It does indicate that a high percentage of Aggregates can be limited to a single Entity, the Root.
[Vernon, 2013, p. 357, emphasis added by me]
Rule 3: Reference Other Aggregates by Identity
This essentially means that you should not reference other aggregates by object reference, but only by ID. The reason for this is to prevent the temptation to modify other aggregates in the same transaction. It also helps keeping queries small.
Prefer references to external Aggregates only by their globally unique identity, not by holding a direct object reference (or “pointer”).
[Vernon, 2013, p. 361]
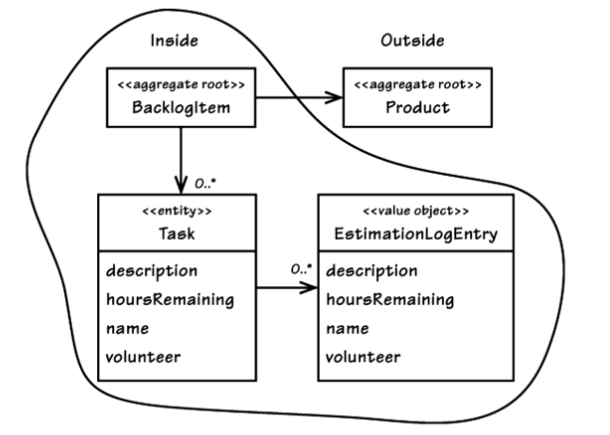
Aggregate reference by object reference (“pointer”) [Vernon, 2013, fig. 10.5, p. 360]
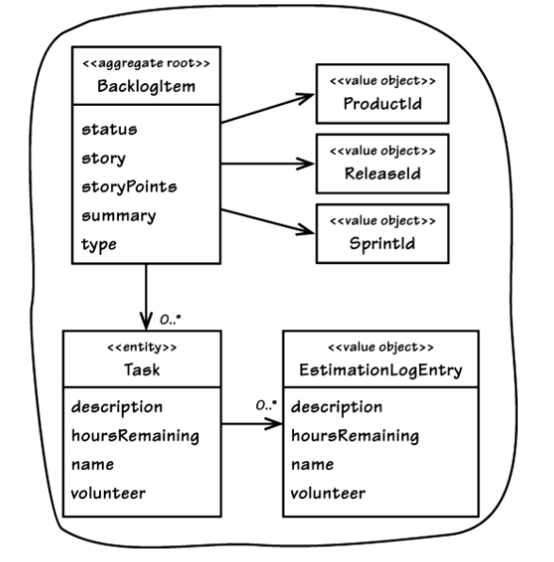
Aggregate reference by (typed) ID only [Vernon, 2013, fig. 10.6, p. 361]
If you don’t hold any reference, you can’t modify another Aggregate. So the temptation to modify multiple Aggregates in the same transaction could be squelched by avoiding the situation in the first place.
[Vernon, 2013, p. 361]
Alternative: Reference by Object Reference, but Lazy-Load, and Use the “From Specific To General” Pattern
The downside of reference by ID is that circular dependencies between aggregates are harder to spot, and that unit tests might become more complicated. Possibly, the Spring JPA / Hibernate mechanism of lazy loading is actually already doing the trick here, as it will only load the referenced aggregate when it is actually needed.

In addition, you should obey the “from specific to general” pattern, which means that you should only reference aggregates that are “more general” than the current aggregate.
Rule 4: Use Eventual Consistency Outside the Aggregate Boundary
This rule effectively boils down to: Update other aggregates using domain events.
[…] if executing a command on one Aggregate instance requires that additional business rules execute on one or more other Aggregates, use eventual consistency.
[Vernon, 2013, p. 364]
See the definition of eventual consistency (as opposed to transactional consistency) above. Eventual consistuency means that the system will be consistent - at some time in the future (“eventually”). This time can be milliseconds, seconds, or even minutes, hours, or days in the future. This may sound strange and somewhat “wrong” for computer scientists whose professional socialization is somewhat based on the idea of “immediate” and “unconditional” consistency. However, if you talk to business people, they will tell you that this is eventual consistency is actually the way the world (and any business) works.
What happens if the subscriber experiences concurrency contention with another client, causing its modification to fail? The modification can be retried if the subscriber does not acknowledge success to the messaging mechanism. The message will be redelivered, a new transaction started, a new attempt made toexecute the necessary command, and a corresponding commit made. This retry process can continue until consistency is achieved, or until a retry limit is reached. If complete failure occurs, it may benecessary to compensate, or at a minimum to report the failure for pending intervention.
[Vernon, 2013, p. 365]
Summary - How Do Use These Rules in Practice?
You should always keep these rules in mind when designing aggregates. It is best to treat them as Architecture Principles. This means that they are not absolute rules that must be obeyed at all times, but rather defaults from which you can deviate if you have a good reason to do so. However, if you deviate from these rules, you need to document the reasons why you have done so.
Consider using Architectural Decision Records (ADRs) for this purpose [ADR Github Organisation], [Wolff & Stal, 2021].
Sources
All references in this page are to Vaughn Vernon’s “Red Book” [Vernon, 2013].
These are good sources on Architectural Decision Records (ADRs):
- ADR GitHub organization. (n.d.). Architectural Decision Records (ADRs). Retrieved October 16, 2023, from https://adr.github.io/
- Wolff, E., & Stal, M. (2021). heise developer Podcast, Episode 86: Architecture Decision Records. Retrieved October 16, 2023, from https://www.heise.de/blog/Episode-86-Architecture-Decision-Records-6183064.html