- Kontakt
-
stefan.bente[at]th-koeln.de
+49 2261 8196 6367
Discord Server
Prof. Bente Personal Zoom
- Adresse
-
Steinmüllerallee 4
51643 Gummersbach
Gebäude LC4
Raum 1708 (Wegbeschreibung)
- Sprechstunde nach Vereinbarung
- Terminanfrage: calendly.com Wenn Sie dieses Tool nicht nutzen wollen, schicken Sie eine Mail und ich weise Ihnen einen Termin zu.
Domain-Driven Design Starter Modelling Process
Domain-Driven Design (DDD) ist ein Konzeptrahmen, kein Designverfahren. DDD – wie in den Büchern von Evans und Vernon beschrieben – bietet konsistente Konzepte und Begriffe, schreibt aber keinen spezifischen Prozess vor. Der DDD Starter Modelling Process schließt diese Lücke: Er ist ein pragmatischer Leitfaden für große Software-Design-Aufgaben, flexibel einsetzbar je nach Situation.

Using DDD Starter as Process Model in the DDD Master Course
Our process in the Digital Sciences Master course Domain-Driven Design of Large Software Systems will be roughly aligned to the Domain-Driven Design Starter Modelling Process which is a pragmatic, practicioners’ guide to approaching large software design tasks.
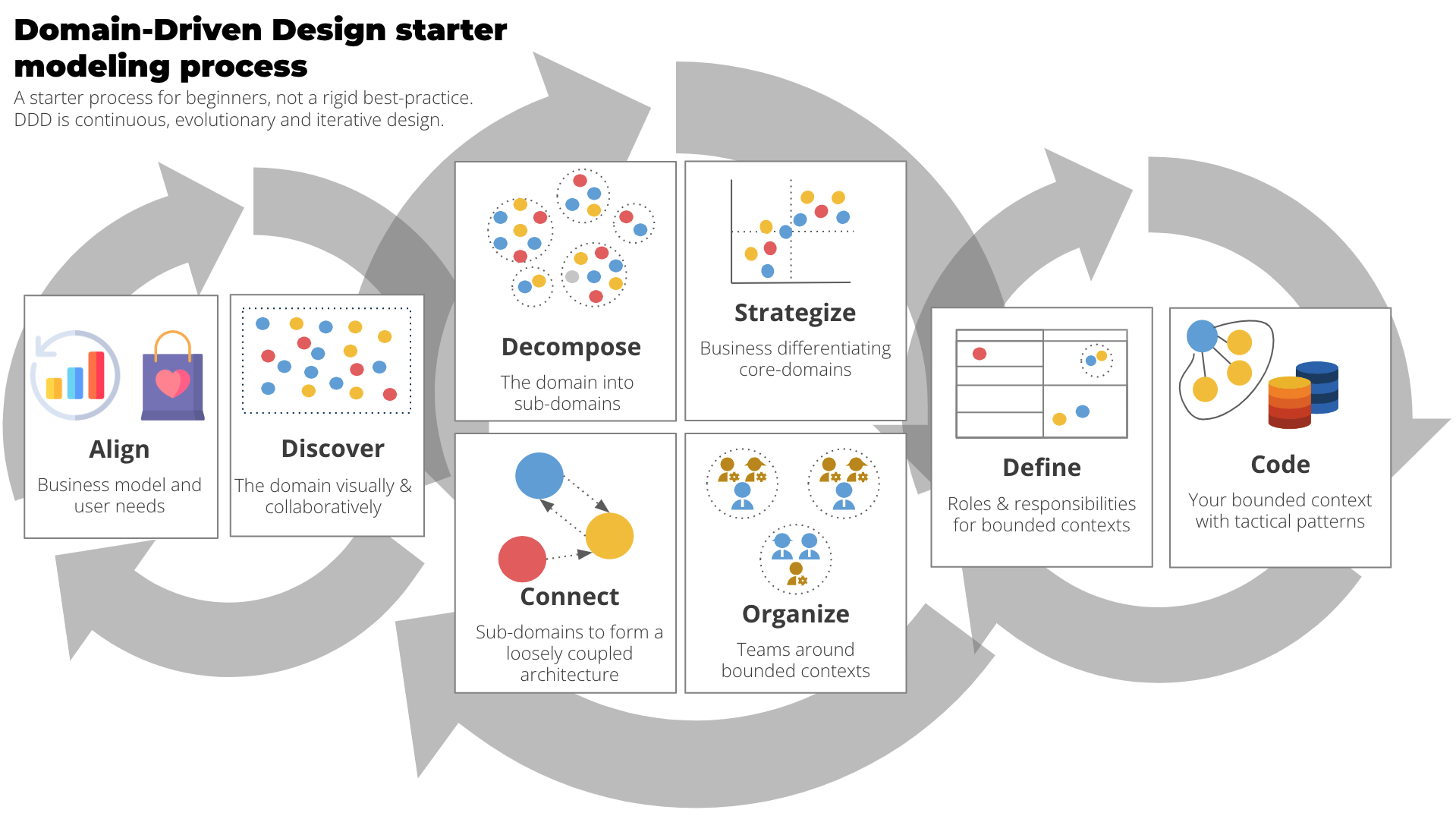
(c) DDD Crew, CC-BY-SA-4.0
Here is how we will cover the phases listed in the above model in the DDD Master course.
Align
In reality, as in this course, this phase usually happens before you start the project. It is about identifying the stakeholders, aligning with them on the goals of the project, and getting their buy-in. In addition, it is about identifying high-level use cases and the main actors involved.
Discover
This phase is for learning about the domain, and trying to pinpoint the essence of it in a semi-formalized way. The 1st subteam (EventStorming) is responsible for this phase. We will use EventStorming (see detailed info page).
Decompose / Strategize / Connect / Organize / Define
In the DDD course, we try to cover these phases jointly, by post-processing the EventStorming results and apply various specification methods. This is covered by the 2nd subteam (Bounded Context). The details can be found on this info page).
The goal is to identify bounded contexts, and their relationship with each other. This way, (largely) autonomous teams can each tackle a bounded context and further specify and implement it, without having to coordinate with other teams too much. The DDD Starter Modelling Process describes these phases as follows.
Decompose
This phase involves breaking down a large system or problem space into smaller, more manageable parts. The aim is to identify distinct areas of functionality or concern, making it easier to tackle complexity. Here, we will try to work with the results of the EventStorming workshop, and draw (sub-)domain boundaries.
Strategize
In this phase, the team evaluates the decomposed parts to determine which are core to the business and which are generic or supporting. By doing this, they can decide where to invest their efforts and resources for maximum business impact. The method we will use is Core Domain Charts.
Connect
In this phase, the relationships between different bounded contexts are identified and defined. This involves specifying how they interact, communicate, and share data, ensuring that the overall system works cohesively. The method to use is Domain Message Flow Modelling.
Organize
This phase is about grouping related functionalities or concepts into bounded contexts. Bounded contexts are clear boundaries within which a particular model is defined and applicable, ensuring that terms and concepts have unambiguous meaning. As method, we will create a Context Map.
Define
Here, the team delves deeper into each bounded context to create a detailed model. This includes defining entities, value objects, aggregates, and domain events, forming the foundation for the software design. In our course, it will be sufficient to identify the main aggregates in each bounded context, and create a container-level model (C4 model level 1 and 2, see next section).
There are explicit tools to specify bounded contexts, like the Bounded Context Canvas. However, this tool seems more suitable for a longterm project, where the team has to maintain a shared understanding of the domain. For our course, this would be somewhat redundant and overly formalistic.
Code
In a full-fledged DDD project, this phase would be about starting the implementation. For time reasons, we will not do this. However, we will identify the main aggregates in each bounded context, and create a container-level model.
This phase will be covered by the 3rd subteam (Components) in the DDD course. The methods we will use in this phase are explained in detail in this info page:
- C4 model (level 1 and 2) for each bounded context.
Sources
There is a commented list of literature and online sources for DDD on this server. For the DDD Starter Modelling Process, the following sources are particularly relevant.
- DDD Crew (2023). Domain-Driven Design Starter Modelling Process
- Evans, E. (2003). Domain-Driven Design: Tackling Complexity in the Heart of Software (1 edition). Addison-Wesley (the “Blue Book”)
- Vernon, V. (2013). Implementing Domain-Driven Design (01 ed.). Addison Wesley (the “Red Book”)
- Vernon, V. (2016). Domain-Driven Design Distilled (1st ed.). Addison-Wesley (the “Green Book”)
Bildquellen
- DDD Crew Overview (banner image): © DDD Crew (CC-BY-SA-4.0) (https://github.com/ddd-crew/ddd-starter-modelling-process)