- Kontakt
-
stefan.bente[at]th-koeln.de
+49 2261 8196 6367
Discord Server
Prof. Bente Personal Zoom
- Adresse
-
Steinmüllerallee 4
51643 Gummersbach
Gebäude LC4
Raum 1708 (Wegbeschreibung)
- Sprechstunde nach Vereinbarung
- Terminanfrage: calendly.com Wenn Sie dieses Tool nicht nutzen wollen, schicken Sie eine Mail und ich weise Ihnen einen Termin zu.
DDD-konforme Package-Konvention
Wenn man ein Domain-Driven Design mit Spring JPA umsetzt (so wie wir das z.B. im ST2-Praktikum machen), dann sollten alle Entwickler:innen im Team dieselben Konventionen für die Strukturierung des Codes verwenden. Nur so bleibt der Code übersichtlich und wartbar. Für ST2 geben wir eine bestimmte Konvention vor, wie die Packages strukturiert werden sollen. In der Praxis gibt es viele verschiedene Varianten hiervon. Diese ist genauso gut wie andere mögliche Konventionen - aber auf irgendetwas müssen wir uns ja einigen.
- Video(s) hierzu
-


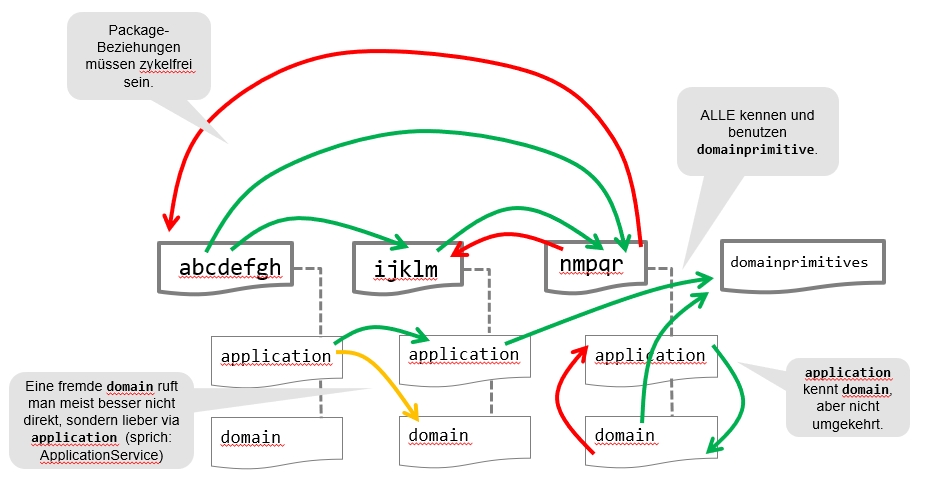
Top-Level-Packages = Aggregates
Mit dieser Konvention gehen wir davon aus, die die Top-Level-Packages in Ihrem Projekt den Aggregates entsprechen. Das sind die “Haupt-Geschäftsobjekte” in Ihrem Projekt. (Siehe die obigen Videos zur Erklärung, was genau Aggregates sind, und wie man sie findet.)
Die Namenskonvention ist einfach der Name des Aggregates in Kleinbuchstaben und Singular (Einzahl).
Abbildung einer Schichtenarchitektur innerhalb jedes Aggregates
Damit ist festgelegt, dass Ihr Softwaresystem vertikal geschnitten ist: Es gibt Packages für die verschiedenen “Teil-Domänen” Ihrer Anwendung. Innerhalb dieser Aggregate-Packages müssen wir dann eine Schichtenarchitektur abbilden. Dabei folgen wir der 4-schichtigen Architektur nach Eric Evans (siehe das “Blue Book”). Diese geht von vier Schichten aus
- Presentation Layer: Hier liegt das User Interface, also z.B. die Web-Oberfläche. Da wir in ST2 auf das Backend fokussieren, spielt diese Schicht bei uns keine Rolle.
- Application Layer: In dieser Schicht werden die Zugriffe, die von außen an das System kommen, verarbeitet. Hier werden (externe) Workflows implementiert, die aus mehreren Schritten bestehen, und Business-Funktionalität in der Domäne aufrufen. Hier liegen Controller, Services, DTOs etc. In den Application Services werden diese Workflows implementiert, und das Lifecycle-Management für die Domänen-Objekte (siehe nächste Schicht) übernommen - also Queries und Speichern von Entitäten.
- Domain Layer: Hier liegt die eigentliche Domäne, also die Geschäftslogik. Hier sind die Entitäten, Value Objects, Repositories etc. zu finden.
- Infrastructure Layer: Hier liegen die technischen Details, also z.B. die Datenbank-Zugriffe, die Konfiguration des Spring-Frameworks, etc. Wir verwenden Spring Data JPA, um den Code zu annotieren, und ersparen uns daher einen expliziten Infrastructure-Layer.
Somit bilden wir die Schichten (2) und (3) in jedem Aggregate ab. Das bedeutet, dass jedes Aggregate zwei Sub-Packages
hat, nämlich application und domain. In dem nachfolgenden Bild sind die Regeln zusammengefasst, und dann danach einzeln
erklärt.
Package application
Hier liegen die Application Services, Controller, Adapter, DTOs, … also alles, was für die Kommunikation mit “außen”
benötigt wird. In erster Näherung kann man sagen: Alles, was in Spring mit @Service oder @RestController annotiert wird,
kommt in dieses Package.
Als Namenskonvention gilt:
- Alles, was mit
@Serviceannotiert wird, heißt...Service - Alles, was mit
@RestControllerannotiert wird, heißt...Controller
Package domain
Dieses Package enthält die Entities, Value Objects, und Repositories des Aggregates. Hier liegt also die eigentliche Geschäftslogik der Anwendung.
Als Namenskonvention gilt:
- Entities und Value Objects werden benannt wie die entsprechenden Domain-Model-Objekte, in CamelCase (z.B.
$BasketClass$) - Repositories werden benannt wie die entsprechende Entity, mit dem Suffix
Repository(z.B.$BasketClass$Repository)