- Kontakt
-
stefan.bente[at]th-koeln.de
+49 2261 8196 6367
Discord Server
Prof. Bente Personal Zoom
- Adresse
-
Steinmüllerallee 4
51643 Gummersbach
Gebäude LC4
Raum 1708 (Wegbeschreibung)
- Sprechstunde nach Vereinbarung
- Terminanfrage: calendly.com Wenn Sie dieses Tool nicht nutzen wollen, schicken Sie eine Mail und ich weise Ihnen einen Termin zu.
Determing Bounded Contexts using DDD Crew Methods
Bounded contexts in DDD provide clear boundaries within which specific domain models are defined and applicable, ensuring consistency and reducing ambiguity. By segregating the system into distinct contexts, it becomes easier to manage complexity, avoid model conflicts, and foster focused, autonomous development teams. Furthermore, bounded contexts facilitate better alignment between the software’s design and the organization’s actual business domains, enhancing clarity and communication. The DDD Crew’s “Starter Modelling Process” provides a set of methods to identify bounded contexts in a systematic way, some of which we will be using in the DDD course.
Before we start: Central DDD concepts for this method
The following concepts are central to this method, and need to be understood by you (if you want to apply the method). They also need to be explained to the participants. The links point to the DDD glossary.
Method Descriptions
In order to obtain a good understanding of the domain, and identifying bounded contexts, we will use a variety of methods as outlined below. Their combination gives us a good overview of the overall domain(s), and how we can split it (or them) into bounded contexts. The methods outlined here are taken from the DDD Starter Modelling Process.
We will not use all methods described in the DDD Starter Modelling Process, but a selection of them. See the section below for a discussion of the methods not used (and why not).
Identify Bounded Context Boundaries from EventStorming Results
EventStorming is a method to identify the domain model of a system via its domain events. In the Big Picture workshop, you usually end up with a lot of domain events ordered into a rough timeline, separated by pivotal events. The pivotal events mark “important” points in time, where something significant happens in the domain. These pivotal events are a good starting point to identify bounded contexts, as they often mark the boundaries between them.
In addition, the Brandolini book (p. 133ff) provides a number of heuristics to identify bounded contexts from the event storming results, if the pivotal events are not sufficient to identify them. Two of these heuristics are summarized by the following quotes (Brandolini assumes a conference management system as an example domain):
Heuristic: look at the business phases … or like detectives would say: “follow the money!” Businesses grow around a well-defined business transaction where some value — usually money — is traded for something else. Pivotal events have a fundamental role in this flow: we won’t be able to sell tickets online without a website, every thing that happens before the website goes live is inventory or expenses, we can start making money only after the Conference Website Launched event.Similarly, after Ticket Sold events, we’ll be the temporary owners of attendees’ money, but they’ll start to get some value back only around the Conference Started event. But the tools and the mental models needed to design a conference, are not the same tools needed to run a conference.
Heuristic: look at the people on the paper roll. An interesting twist might happen when dealing with different personas. Apparently, the flow should be the same, but it’s not. Conference organizers or track hosts can invite some speakers, while others submit their proposals in the Call for Papers. The flows can be independent in the upstream part of the flow (you may want to skip a cumbersome review process for a superstar speaker). Downstream they’re probably not (on the conference schedule, you want the same data, regardless of how you got it).
Core Domain Charts
In Domain-Driven Design (DDD), Core Domains, Supporting Domains, and Generic Domains are used to categorize different parts of a business. See DDD Glossary for a more detailed definition.
Core Domain Charts are a tool to classify (sub-)domains into these three categories. In addition, we found this chart quite useful to identify bounded contexts for teams (especially, if teams handle more than one aggregate). Using the core domain chart, you can identify which (sub-)domains “matter most”, so that each team gets one clear focus area.
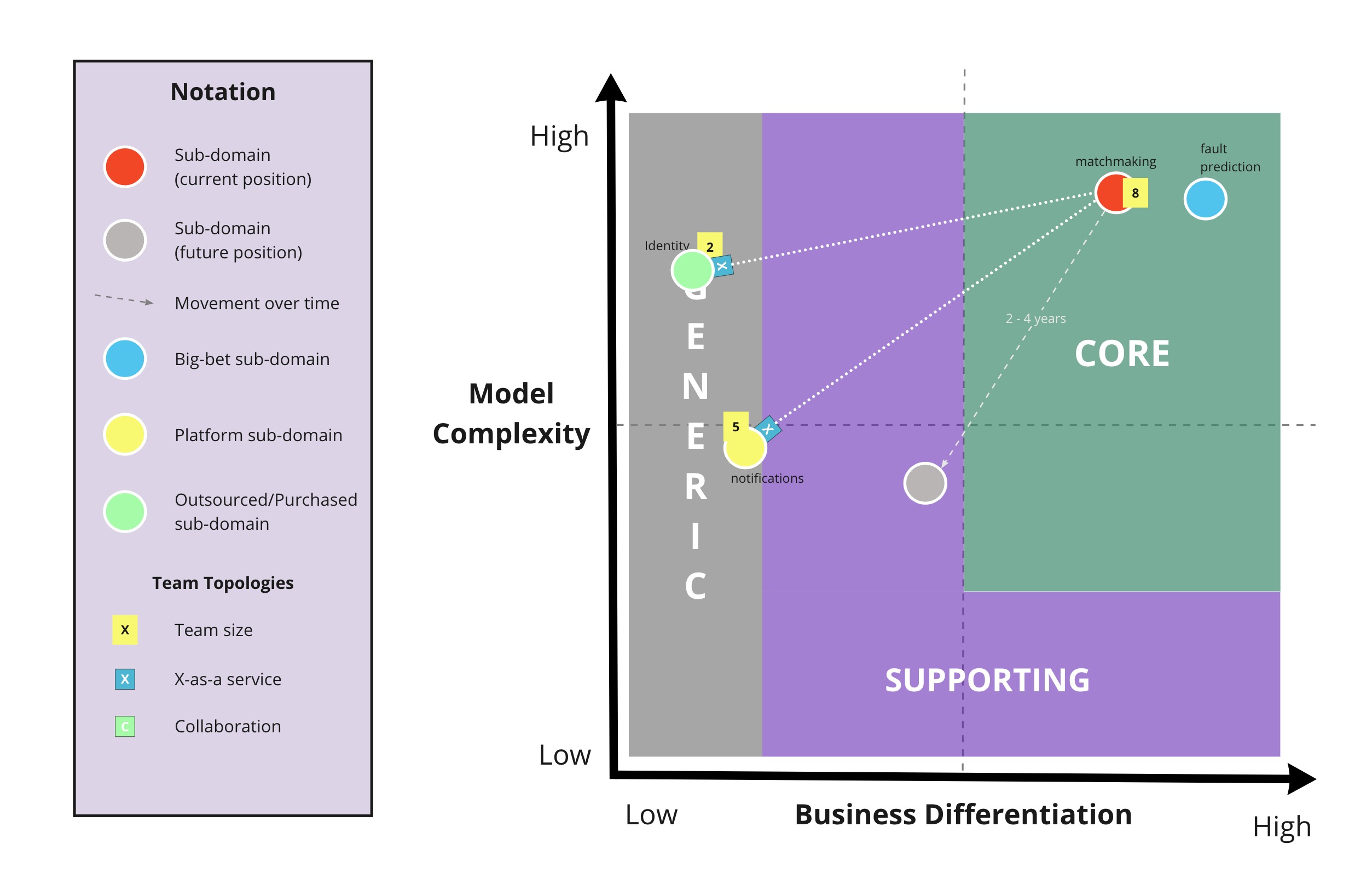
Core Domain Charts help you to visualise the strategic importance of each (sub)domain or business capability in your architecture allowing you to make business model-aligned architectural decisions.
[DDD Crew, Core Domain Charts, 2023]
A good source for further and in-depth information is [Tune, 2020].
Domain Message Flow Modelling
Domain Message Flow Modeling is a technique used in domain-driven design (DDD) to understand and visualize the flow of messages and domain events between bounded contexts.
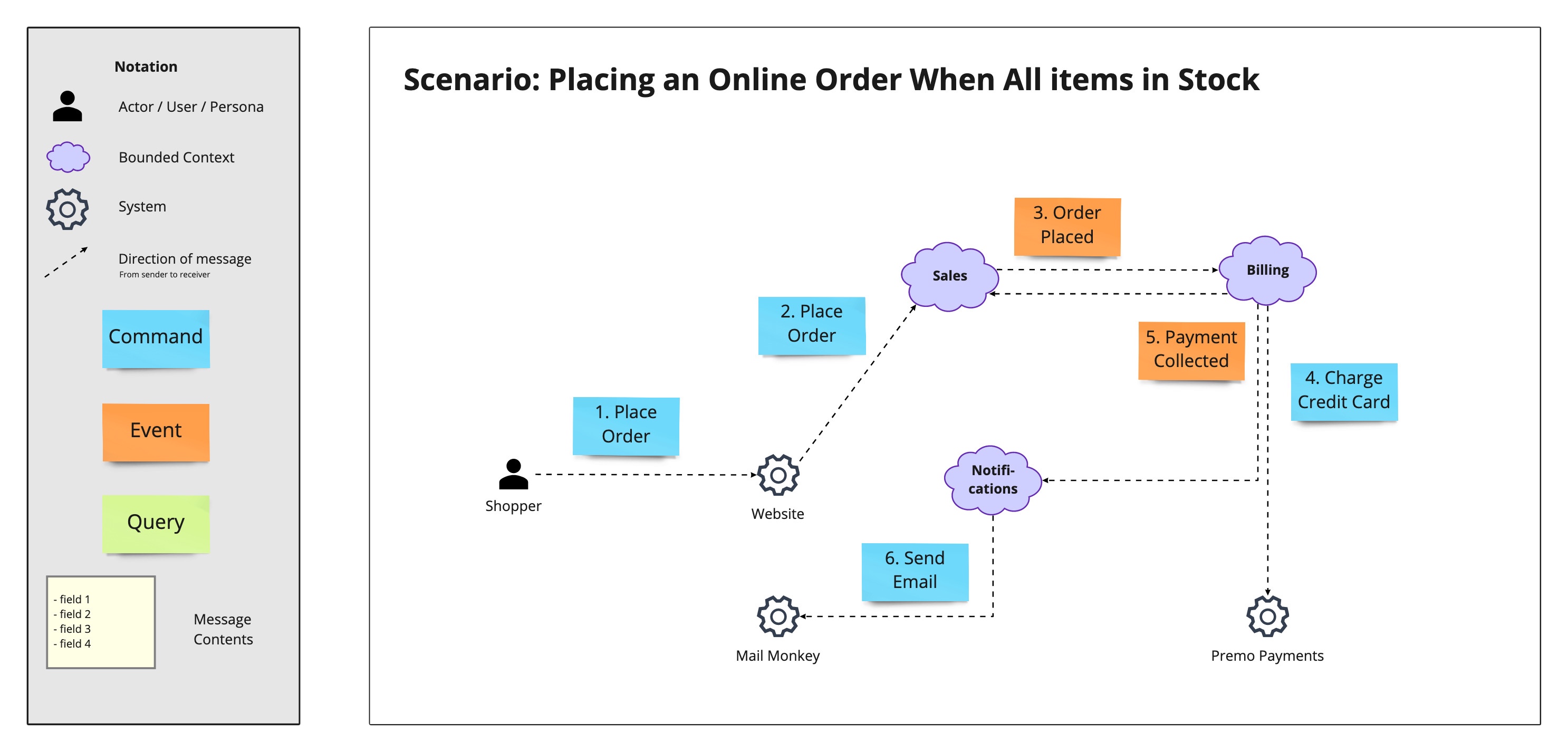
The notation allows you to differentiate between commands, events, and queries, and to specify the payloads of these messages. In addition, it allows you to specify the direction of the message flow, and the order of their execution. It can be seen as an informal (or “less formal”) kind of flow diagram, depicting data / control flow in between bounded contexts and (external) systems.
The method is best described in a dedicated repo by the DDD Crew https://github.com/ddd-crew/domain-message-flow-modelling.
The method is especially useful to identify the relationships between bounded contexts, and even more so if there is a clear commitment to Event-Driven Architecture (EDA) in the project.
Context Map
DDD’s strategic design goes on to describe a variety of ways that you have relationships between Bounded Contexts. It’s usually worthwhile to depict these using a context map.
(Martin Fowler in his very instructive post on bounded contexts). Or, as Vaugn Vernon writes in the “red book” (p. 87):
The Context Map […] is […] a simple diagram that shows the mappings between two or more existing Bounded Contexts.
A great explanation of what context maps are can be found in Michael Plöd’s speakerdeck about them In addition, there is an extensive slide deck of my own, however still in German, as I haven’t translated it yet.
The DDD crew provides detailed material about context mapping. We will use their notation. However, for clarity we will combine this notation with Martin Fowler’s idea to draw the relationship pattern between aggregates, not whole bounded contexts. So it will be a combination of these two:
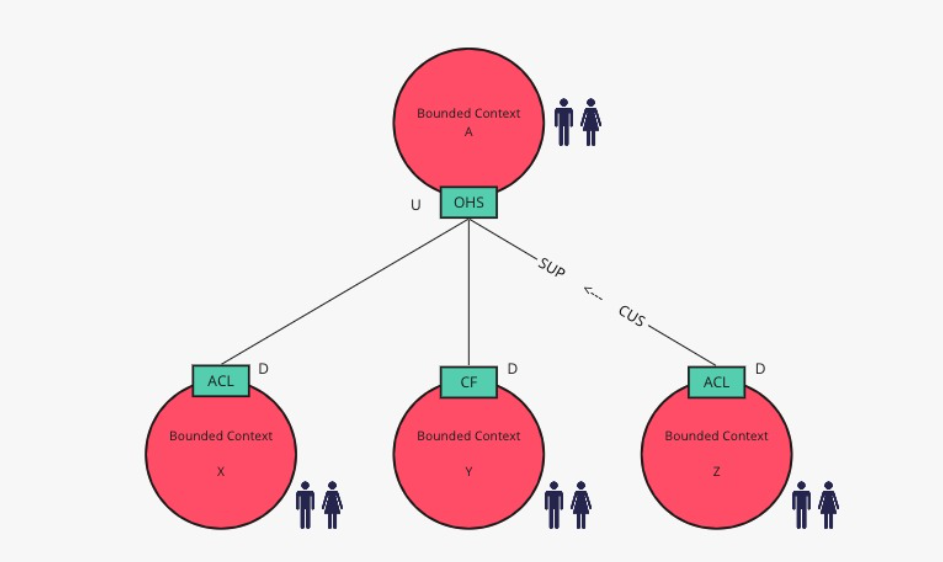
(DDD Crew’s view on context mapping)
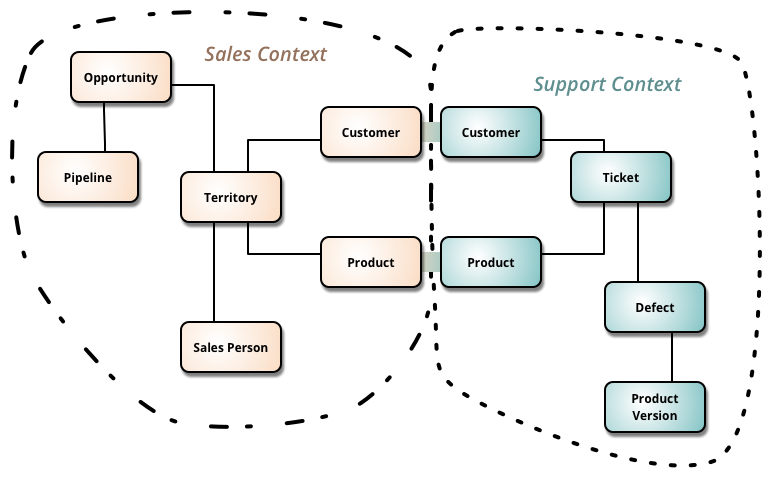
(Martin Fowler’s view on context mapping)
How to tackle this in an Academic Course
This section contains advice for student teams responsible for this topic in the DDD course.
The moderators as well as the participants require some familiarity with the methods. Therefore,
plan some time to read and discuss in your preperation team. Plan also a retrospective,
where you analyse what went well and what could be improved. Before workshop, you need to do the following:
- Read the available sources on methods summed up on this page.
- Use the domain from the EventStorming workshop as a starting point. Familiarize yourself with the results from that workshop. If needed, you can assume that we hang up the EventStorming results again, physically in the room.
- Fully understand the central DDD concepts listed above, and prepare to explain them to your fellow course members (when they attend the workshop organized by your team).
- Write a workshop concept where you define how you want to run the workshop. Be aware that you have limited
time, so you need to discuss how much time you want to dedicate to each part of it. You should run the
workshop in a timeboxed fashion, so that you have covered all the areas at the end of the workshop.
Partipants may get “homework” to do (to complete the modelling offline, outside the workshop).
The workshop concept needs to address the following aspects. Please check this plan with Prof. Bente before the workshop.
- Selection of methods, and the order in which you present them (you need to cover the three required methods above, but feel free to add others of your choice)
- What technical decisions you will have to make (e.g. databases, message bus, etc.) and how you want to decide this in the workshop. Your goal should be that this is not just a “diagram creation workshop”, but a real architecture decision workshop.
- Detailed time schedule
- What and how much input you want to give to the participants
- How to do a retrospective of the workshop with the participants, and how to document the feedback
- Conduct and document the case study workshop.
- Conduct, and document a retrospective with the other course members. The goal is to identify what went well and what could be improved.
Methods not used in this DDD course (and why)
The DDD Crew’s “Starter Modelling Process” contains a number of additional methods, which we will not use in this course, for the following reasons:
Bounded Context Canvas
The bounded context canvas (https://github.com/ddd-crew/bounded-context-canvas) helps to sum up the constituents of a bounded context in somewhat standardized, compact form. Practioners like Kathi Hirth (member of the DDD Crew) swear by it (as expressed during a guest lecture in my DDD course in 2024).
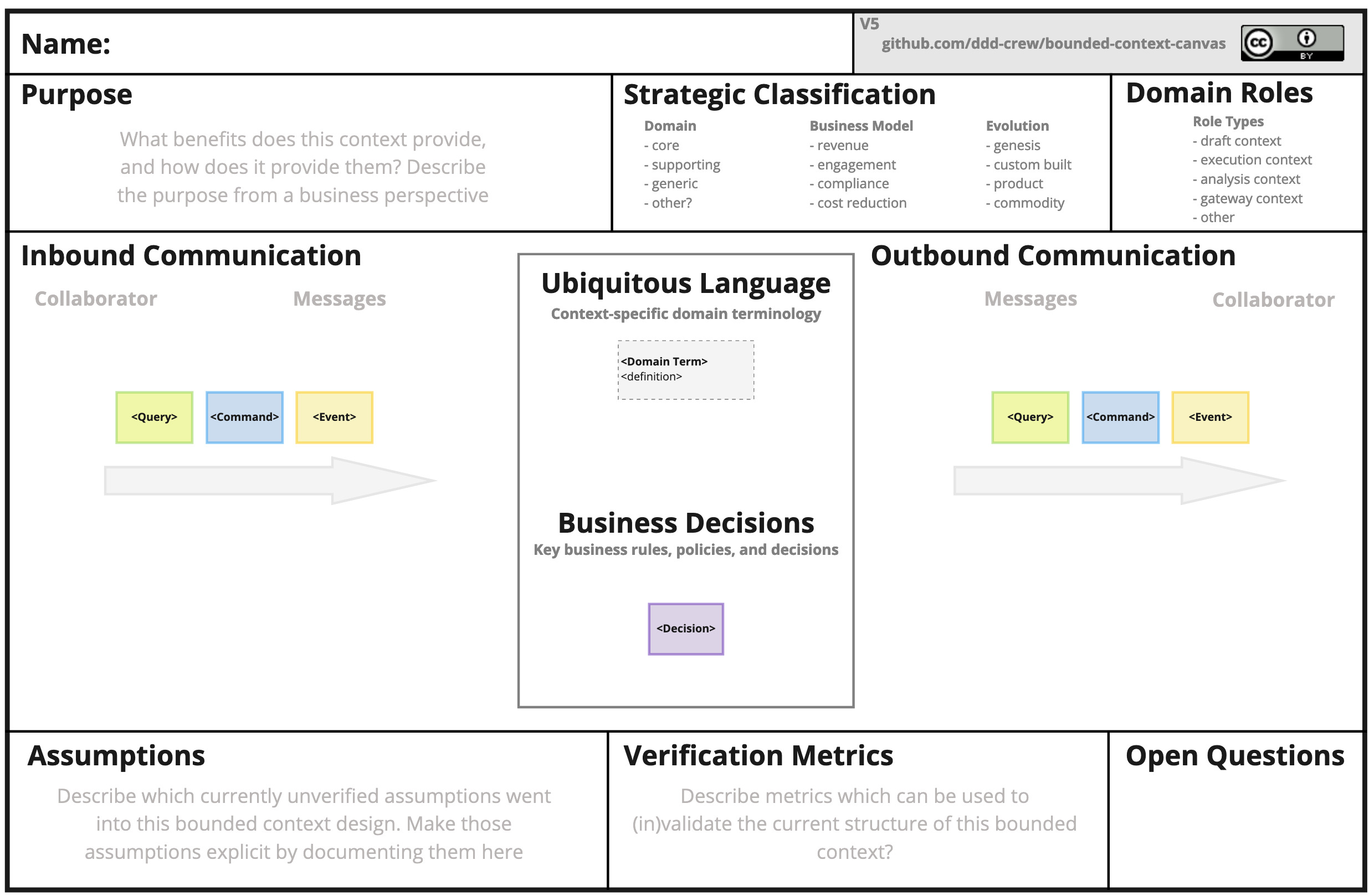
However: We don’t use it in teaching. It seems more suitable for a longterm project, where the team has to maintain a shared understanding of the domain. In the simulated, short-term setting of a course like DDD, students don’t have enough real-world data filled in the canvas in sensible way. Therefore, the canvas deteriorates in such a setting into a “theoretical exercise”.
Aggregate Design Canvas
The Aggregate Design Canvas is a DDD Crew tool to design aggregates in a systematic way. We skip it in the course for much the same reasons as the Bounded Context Canvas.
Sources
In the DDD commented literature list, there is are several sections with sources related to this topic.
- The “Big Picture” for applying DDD lists sources elaborating on the overall process of applying DDD, including the strategic design phase.
- The section “Using DDD in the Design Process: Specific Concepts and Methods” sums up sources describing specific methods, as listed above.
Image Sources
- Core Domain charts (banner image left part, and dedicated image): © DDD Crew (CC-BY-SA-4.0) (https://github.com/ddd-crew/core-domain-charts)
- Domain Message Flow Modelling (banner image middle part, and dedicated image): © DDD Crew (CC-BY-SA-4.0) (https://github.com/ddd-crew/domain-message-flow-modelling)
- DDD Crew's view on context mapping: © DDD Crew (CC-BY-SA-4.0) (https://github.com/ddd-crew/context-mapping)
- Martin Fowler's view on context mapping (banner image right part, and dedicated image): © Martin Fowler, 2014 (https://martinfowler.com/bliki/BoundedContext.html)